在 OpenAI ChatGPT Token 限制下如何進行有效的使用策略。
Background
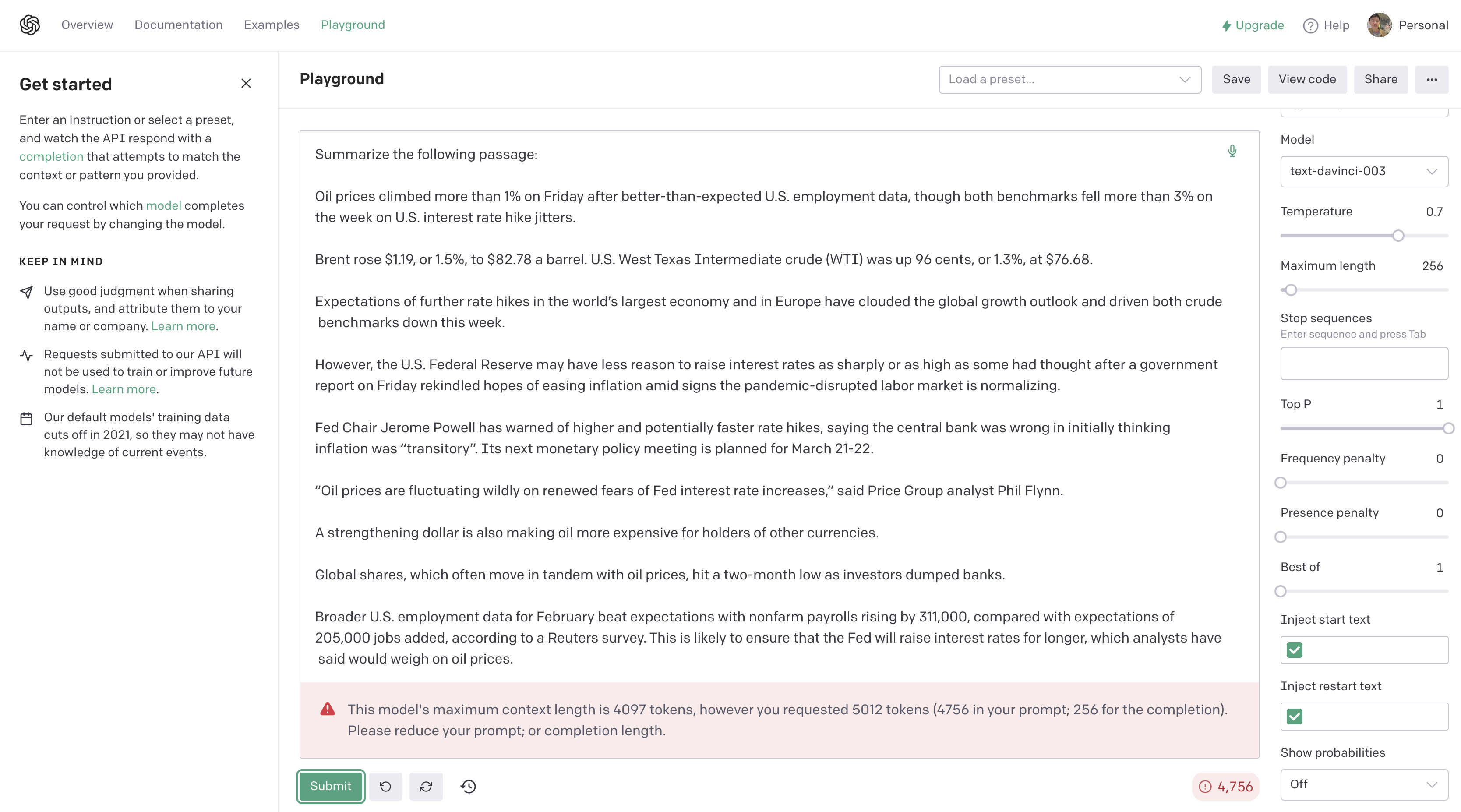
在使用 OpenAI ChatGPT 時,我們會發現 ChatGPT 是有 Token Limits 的限制。這意味著每次我們只有一定數量的 Token 可以使用,而 Token 的數量越多,可以使用的模型能力也越強大。因此,如何解決 Token Limits 的問題,成為了我們所關心的問題。在本篇文章中,我們將會介紹如何繞過 Token Limits 的限制。
Tokens Limits
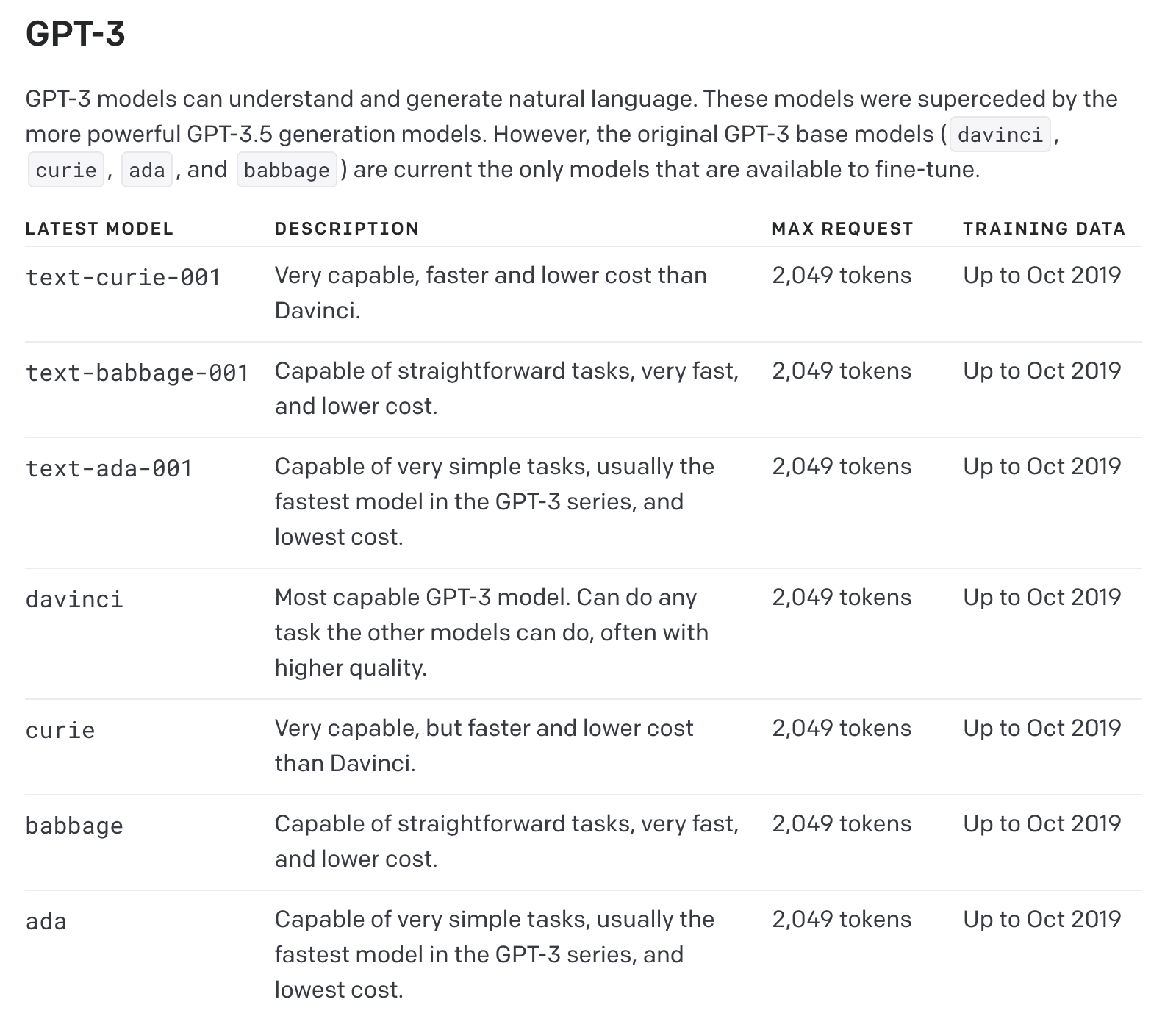
下列是目前各模型的 Max Request Tokens,詳細說明可以參考 GPT-3 Documentation。
Solution
OpenAI Research 中提供了一個很好的解決方案,即使用人類反饋進行書籍摘要這篇所用的方法,實作步驟如下。

- 將原始文本分為不同的部分,每個部分進行摘要。
- 將各部分的摘要再次進行摘要,形成更高層次的摘要。
- 摘要過程一直持續,直到得到完整的摘要。
- 針對最後摘要進行我們期望的查詢或分析。
而如何拆分文本 Tokens 有很多 Python 的 NLP 包可以幫助我們計算 NLP Token。以下是一些常用的 Python NLP 包:
NLTK(Natural Language Toolkit): NLTK 是一個用於自然語言處理的 Python 包,提供了大量的功能,包括斷詞、標記、命名實體識別、詞幹提取、詞形轉換等。
SpaCy: SpaCy 是一個現代的自然語言處理庫,可用於斷詞、命名實體識別、詞性標記等。
TextBlob: TextBlob 是一個 Python 庫,用於處理自然語言處理任務,如情感分析、斷詞、詞性標記等。
Gensim: Gensim 是一個用於文本分析的 Python 庫,可以用於斷詞、文檔相似性比較等。
AllenNLP: AllenNLP 是一個基於 PyTorch 的自然語言處理庫,可以用於文本分類、序列標記、機器翻譯等。
Keras Tokenizer: Keras Tokenizer 是 Keras 庫中的一個類,可以用於將文本轉換為序列,並將序列轉換為 NLP Token。
Transformers: Transformers 是 Hugging Face 中一個非常強大的自然語言處理庫,其核心是基於 Transformer 模型的深度學習算法。它提供了許多預訓練模型,包括 BERT、GPT、GPT-2、RoBERTa 等,並且支持多種任務,例如文本分類、命名實體識別、情感分析、問答等等。此外,它還提供了方便的工具和函數,幫助用戶輕鬆地使用這些預訓練模型進行自然語言處理任務。
Tiktoken:Tiktoken 是 OpenAI 本身開發的一種用於模型的快速 BPE 標記器。
實驗後發現使用 NLTK 計算的 Tokens 數與 OpenAI 分詞器 不一致,但差異很小。Transformers 的 Tokens 計數與 OpenAI Tokens 分詞器是一致的。但處理速度慢 Tiktoken 3-6 倍
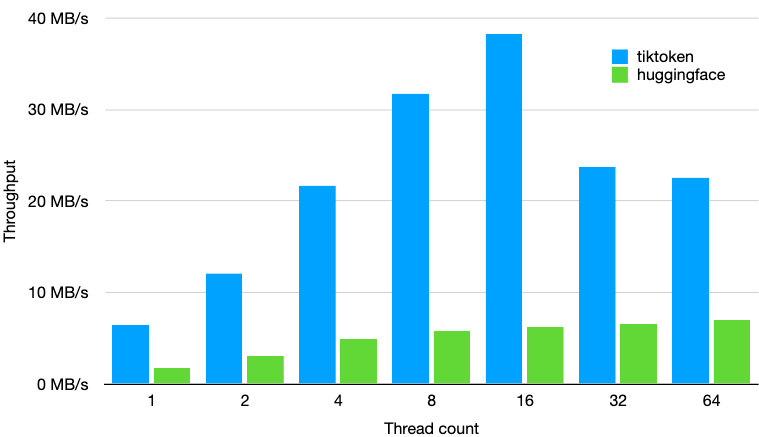
以 GPT-2 的分詞器,使用 tokenizers==0.13.2、transformers==4.24.0 和 tiktoken==0.2.0,在 1GB 的文本上進行的效能測試,結果如上圖,基於效能與正確性,以下選擇 Tiktoken 作為範例。
Install Packages
pip install openai
pip install tiktoken
Import Packages
import os, openai, tiktoken
Codebase
透過 count_tokens 我們可以計算目前文本用了多少 Tokens.
def count_tokens(filename, encoding_name: str) -> int:
encoding = tiktoken.encoding_for_model(encoding_name)
with open(filename, 'r') as f:
text = f.read()
num_tokens = len(encoding.encode(text))
return num_tokens
model_name = "gpt-3.5-turbo"
filename = "/Users/nero/Desktop/Github/jupyter/Brent_oil_price_forecast_for_2023.txt"
num_tokens = count_tokens(filename, model_name)
print("Number of tokens: ", num_tokens)

接下來將文本分解為 1,000 個標記和重疊的 100 個標記的塊,以確保不會因分解文本而丟失任何信息。
def file_to_chunks(filename, encoding_name: str, chunk_size=1000, overlap=100):
encoding = tiktoken.encoding_for_model(encoding_name)
with open(filename, 'r') as f:
text = f.read()
tokens = encoding.encode(text)
num_tokens = len(tokens)
chunks = []
for i in range(0, num_tokens, chunk_size - overlap):
chunk = tokens[i:i + chunk_size]
chunks.append(chunk)
return chunks
生成您的 OpenAI secret API key 並將其設置為名為 OPENAI_API_KEY 的環境變量,OpenAI secret API key 如何生成請閱讀 Where do I find my Secret API Key?
os.environ["OPENAI_API_KEY"] = 'sk-...'
openai.api_key = os.getenv("OPENAI_API_KEY")
將各部分的摘要再次進行摘要,形成更高層次的摘要,一直持續過程,直到得到完整的摘要。
model_name = "gpt-3.5-turbo"
filename = "/Users/nero/Desktop/Github/jupyter/Brent_oil_price_forecast_for_2023.txt"
prompt_response = []
encoding = tiktoken.encoding_for_model(model_name)
chunks = file_to_chunks(filename, model_name)
for i, chunk in enumerate(chunks):
prompt_request = "Summarize this article: " + encoding.decode(chunks[i])
messages = [{"role": "system", "content": "This is text summarization."}]
messages.append({"role": "user", "content": prompt_request})
response = openai.ChatCompletion.create(
model=model_name,
messages=messages,
temperature=0.5,
max_tokens=1500,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
prompt_response.append(response["choices"][0]["message"]['content'].strip())
prompt_request = "Consoloidate these article summaries: " + str(prompt_response)
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt_request,
temperature=0.5,
max_tokens=1500,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
article_summary = response["choices"][0]["text"].strip()
print(article_summary)
透過這樣的方式我們可以在不踩到 Max Request Tokens 的限制,得到最後摘要的結果,針對最後結果我們可以再進行所期望的查詢或分析,像是這篇新聞的市場情緒是正向還是反向的。

Reference
comments powered by Disqus