“初探機器學習,Pytorch 基礎!”
簡介
Tensor
Tensor 即張量表示的是一個多維的矩陣,零為是一個點,一維是向量,二維是平面矩陣,多為相當連續的數組。
torch.Tensor是一中包含單一數據類型的多維陣列,Torch定義了七種CPU張量類型和八種GPU張量類型,torch.Tensor默認的tensor類型為(torch.FlaotTensor)。
| 數據type | CPU張量 | GPU張量 |
|---|---|---|
| 32位浮點 | torch.FloatTensor | torch.cuda.FloatTensor |
| 64位浮點 | torch.DoubleTensor | torch.cuda.DoubleTensor |
| 16位浮點 | N / A | torch.cuda.HalfTensor |
| 8位整數(無符號) | torch.ByteTensor | torch.cuda.ByteTensor |
| 8位整數(帶符號) | torch.CharTensor | torch.cuda.CharTensor |
| 16位整數(帶符號) | torch.ShortTensor | torch.cuda.ShortTensor |
| 32位整數(帶符號) | torch.IntTensor | torch.cuda.IntTensor |
| 64位整數(帶符號) | torch.LongTensor | torch.cuda.LongTensor |
以下範例為利用一個 python 的 list 建立一個tensor。
>>> torch.FloatTensor([[1, 2, 3], [4, 5, 6]])
1 2 3
4 5 6
[torch.FloatTensor of size 2x3]
也可以創建一個內容全為0的 Tensor
>>> torch.zeros((3, 2))
tensor([[0., 0.],
[0., 0.],
[0., 0.]])
或者亂數產生隨機初始值
>>> torch.randn((3, 2))
tensor([[ 1.8436, -0.2691],
[ 0.5289, -1.6964],
[-0.3884, -0.0773]])
可以透過 index 指定改變的數值
>>> a = torch.Tensor([[1, 2, 3], [4, 5, 6]])
>>> a[1, 2]=100
>>> print(a)
tensor([[ 1., 2., 3.],
[ 4., 5., 100.]])
torch.Tensor 可轉換為 numpy.ndarray。
>>> a = torch.FloatTensor([[1, 2, 3], [4, 5, 6]])
>>> numpy_a = a.numpy()
>>> print(numpy_a)
array([[1., 2., 3.],
[4., 5., 6.]], dtype=float32)
也可以從 numpy.ndarray 轉換為 torch.Tensor。
>>> a = np.array([[2,3],[4,5]])
>>> torch_a = torch.from_numpy(a)
>>> print(torch_a)
而需要透過 GPU 加速時只需要加上 cuda()。
if torch.cuda.is_available():
a_cuda = a.cuda()
print(a_cuda)
Variable
Variable 是 PyTorch 中一個重要的概念,Variable 本質上與 Tansor 沒有區別用以保存數據,差別在於 Variable 用以保存神經網路訓練期間變化的值,即我們網路可學習得參數,而 Tensor 不儲存訓練過程中學習的值。
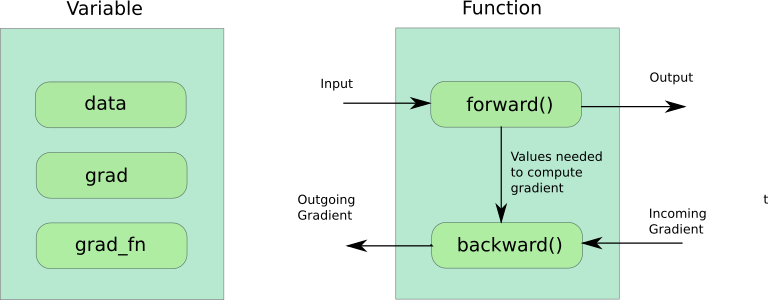
在真實世界中我們可以將任何問題轉換為一個 function of x 即 𝑓(𝑥),機器學習則是希望盡量減少這個 function 與真實世界的差距,在網路訓練的過程中 input 經過 forward() 最後輸出 output ,可透過設定requires_grad=True在 value 經過 forward() 時告知backward()在發生反向傳播梯度(backpropagation)時便會自動計算 gradient 達到 Autograd 的效果。
Module
在 PyTorch 中所有的神經網路都是基於 torch.nn.Module ,且 Module 可以以樹狀結構巢狀包含其它 Module ,以下為一個如何建立 Module 的實際範例。
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)# submodule: Conv2d
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
Optimizer
在機器學習中我們需要透過在調整參數來使 loss function 最小化, Optimizer 算是調整參數更新的策略,Pytorch 中 torch.optim 實作了各種優化算法,下列為如何在 PyTorch 中建立一個 Optimizer。
optimizer = torch.optim.SDG(model.parameters(), lr=0.01, momentum = 0.9)
我們使用 Stochastic Gradient Descent (SGD) 作為我們優化的策略並帶入學習率 為 0.01 與動量 0.9 ,在每回我們需要將輸出的數值與實際數值帶入 loss function 然後將 optimizer 的 gradient 歸零,接著透過 loss.backward() 反向傳播算出
gradient 決定要走的方向,最後只需要 optimizer.step() 就可以透過 gradient 更新參數。
loss = loss_func(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
參考資料
comments powered by Disqus